Image classification is essential to facilitate image retrieval from large image databases based on queries posed by a user. Research in classification based on high and low level analysis of image content (colour, texture, objects) only has been going on for over fifteen years now. Our research focuses on using context information (e.g. metadata, like EXIF data, embedded in image files) along with image content information, to improve image classification.
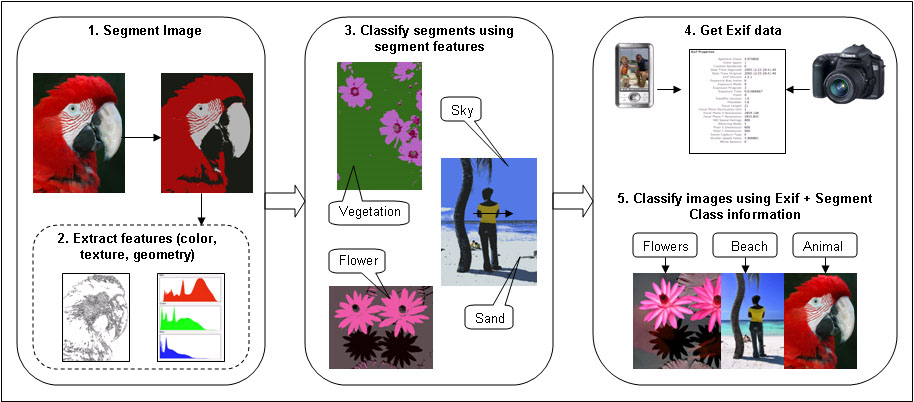
The method tried out currently performs image classification in two stages. In the first stage (steps 1, 2, 3 of figure below), images are segmented and classified based on colour and texture features of content of the image, using a decision tree classifier. In the second stage (steps 4 and 5), whole images are classified based on segment class information obtained before, along with context information (Exif tags) again using a decision tree classifier. The results indicate that using content information along with context information can improve image classification.
It is possible to improve image classification further in the by using a larger set of features for content and a greater number of Exif tags than used currently. There can be other image classification strateties (other than a two stage classification) that may perfom better. To make image classification useful in practice, it has to be made automatic and it should be able to deal with more complex queries from user. Also, it is possible to obtain addition context information from content information (for instance from text appearing in images). Our future research is aimed in these directions.
Sabine Süsstrunk
Patrick Zbinden
This work is supported by National Competence Center in Research on Mobile Information and Communication Systems (NCCR-MICS), a center supported by the Swiss National Science Foundation under grant number 5005-67322, and by K-Space, the European Network of Excellence in Knowledge Space of semantic inference for automatic annotation and retrieval of multimedia content.